
Data Automations Overview
The Data Service lets you bring any kind of data into Marq and visualize it. It is a powerful way to automate content creation for users to populate multiple placeholders (text, images) within a Marq template.
What is the Data Service?
The Data Service facilitates:
- Uploading datasets to Marq manually, from an integration, or via API.
- Using the Data Service allows Marq customers to flexibly add data to their projects without sacrificing any of the real-time collaboration and granular access control features that are central to the Marq platform.
How to use the API
Authentication
Every request to the Data Service should be authenticated with valid user credentials. Marq supports OAuth 2.0 authentication.
Versioning
Each request to the Data Service should specify, as part of the request header, a version number. The version number specified denotes which version of the Data Service API the client expects. The latest, and only, version currently available is Version 1. To add versioning, the HTTP request should have an Accept Header in the following format: Accept: application/json;v=1.
Rate Limits
To prevent abuse and undue stress on the Data Service, the API has a rate limiting feature (sometimes called throttling) that restricts the requests of users.
Marq recommends that you design your integration to gracefully handle this rate limit error. One way of doing that would be to have your integration sleep for 60 seconds when this error is encountered, and then subsequently retry the request. Alternatively, you might choose to implement exponential backoff, an error handling strategy whereby you periodically retry a failed request with progressively longer wait times between retries until either the request succeeds or the certain number of retry attempts is reached.
| Free | Standard | Enterprise | |
|---|---|---|---|
| Hard Refresh Interval | N/A | 60 seconds since last | 30 seconds since last |
| Soft Refresh Interval | N/A | 60 seconds since last | 30 seconds since last |
| User API Rate | 200 requests per minute | 200 requests per minute | 500 requests per minute |
| File Size Limit | 2 MB | 2 MB | 2 MB |
How does the Data Service work
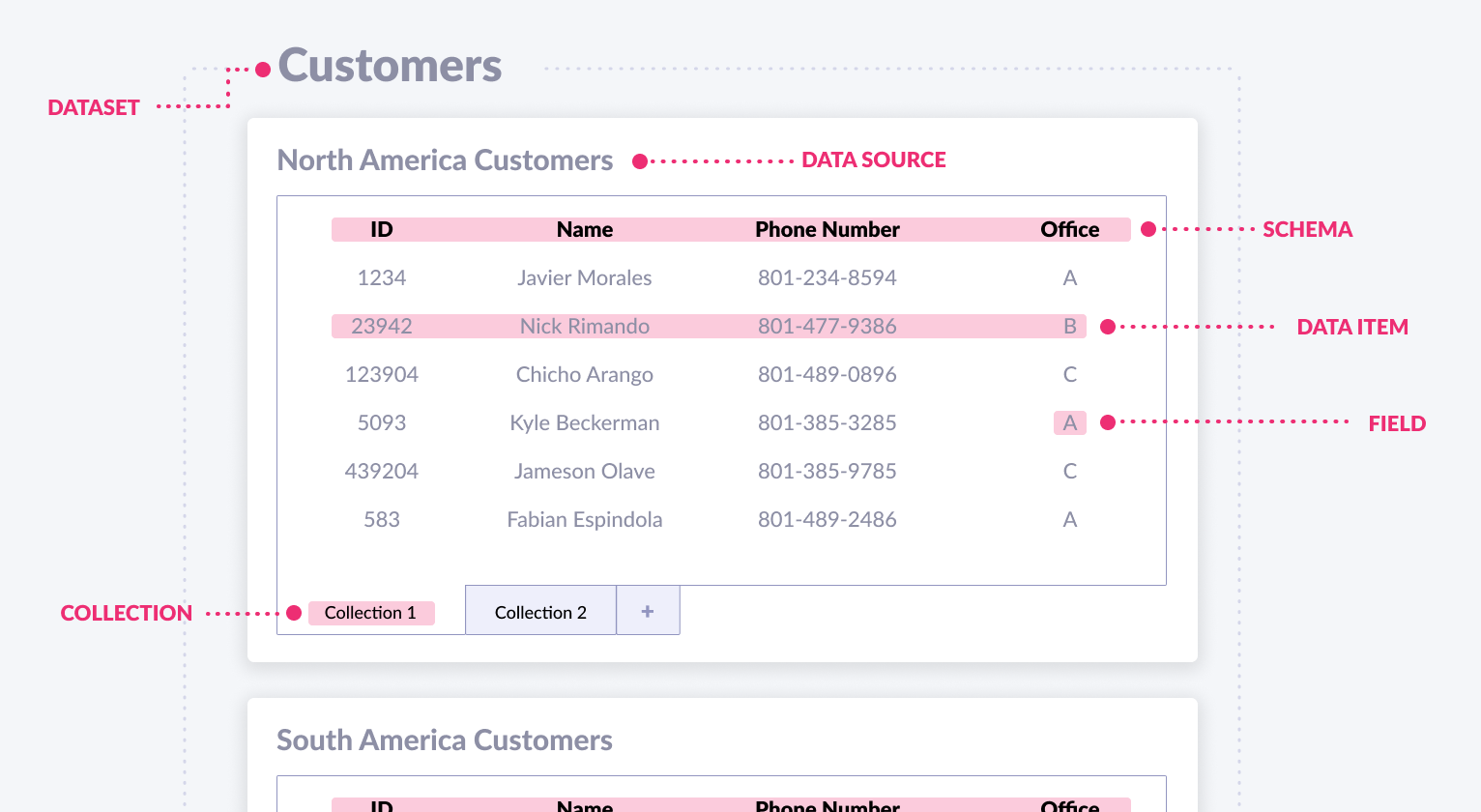
Data Automation Structure
Data Automations consist of the following structure:
- Data Set
- Data Source
- Collection
- Data Item
Data set
A data set is a logical grouping of data sources and can be thought of as a group of related spreadsheet files. A data set can contain multiple related data sources, but a data source can be a member of at most one data set.
Data Source
A data source is comprised of collections and can be thought of as a spreadsheet file, structured like an Excel file or a Google Sheets project. A data source can optionally belong to at most one data set, but it can also exist without belonging to any data set.
Collection
A collection is a container inside of a data source. A data source can have many collections, but a collection can only belong to one data source. A collection can be thought of as a tab or individual sheet in a spreadsheet file. In the case of a CSV file, there would only be a single collection. Each collection contains a schema, items, collection properties, and metadata collections.
Schema
Each collection has one schema which describes the content of the collection. You can think of the schema as a header row in a spreadsheet (see Illustration A). The schema is made up of field definitions.
Item
An item is a container inside of a collection and can be thought of as a single row in a spreadsheet. A collection can have many items, but an item can only belong to one collection. Each item is made up of fields.
Field
Each field holds a value and can be thought of as a single cell in a spreadsheet. An item can have many fields, but a field can only belong to one item.
Field Definition
Each field definition describes the name and type (string, number, boolean, etc) of the field. It also specifies whether or not the field is a primary key, the order in the primary key if it is a primary key, and the default value for the field. The name of the field can be thought of as the column name in a spreadsheet.
Primary keys act as identifiers for the items they belong to. If an item's field value is not specified, the default value from the field definition will be used.
Access to Data Automation
Data Set and Data Source Grants
Each data set and source must have one or more associated source grant(s). The source grants' purpose is to specify the authorization level for a user trying to access the data via Marq's Data Automation.
Each source grant consists of an access level, an authorization type, and an identifier string saying which user or account the authorization belongs to.
Both the Data Set and Data Source have grants which allow you to choose to give access to the data set Customers for all users, but then give Jane Smith, a user in Canada, only access to customers in the North America data source.
| Grant Type | Description |
|---|---|
user | This level grants access to individual users if their Marq id is equal to the grant's identifier string. |
account | This level grants access to every user on the Enterprise/Team account specified by the grant's identifier string. |
Updated over 1 year ago